

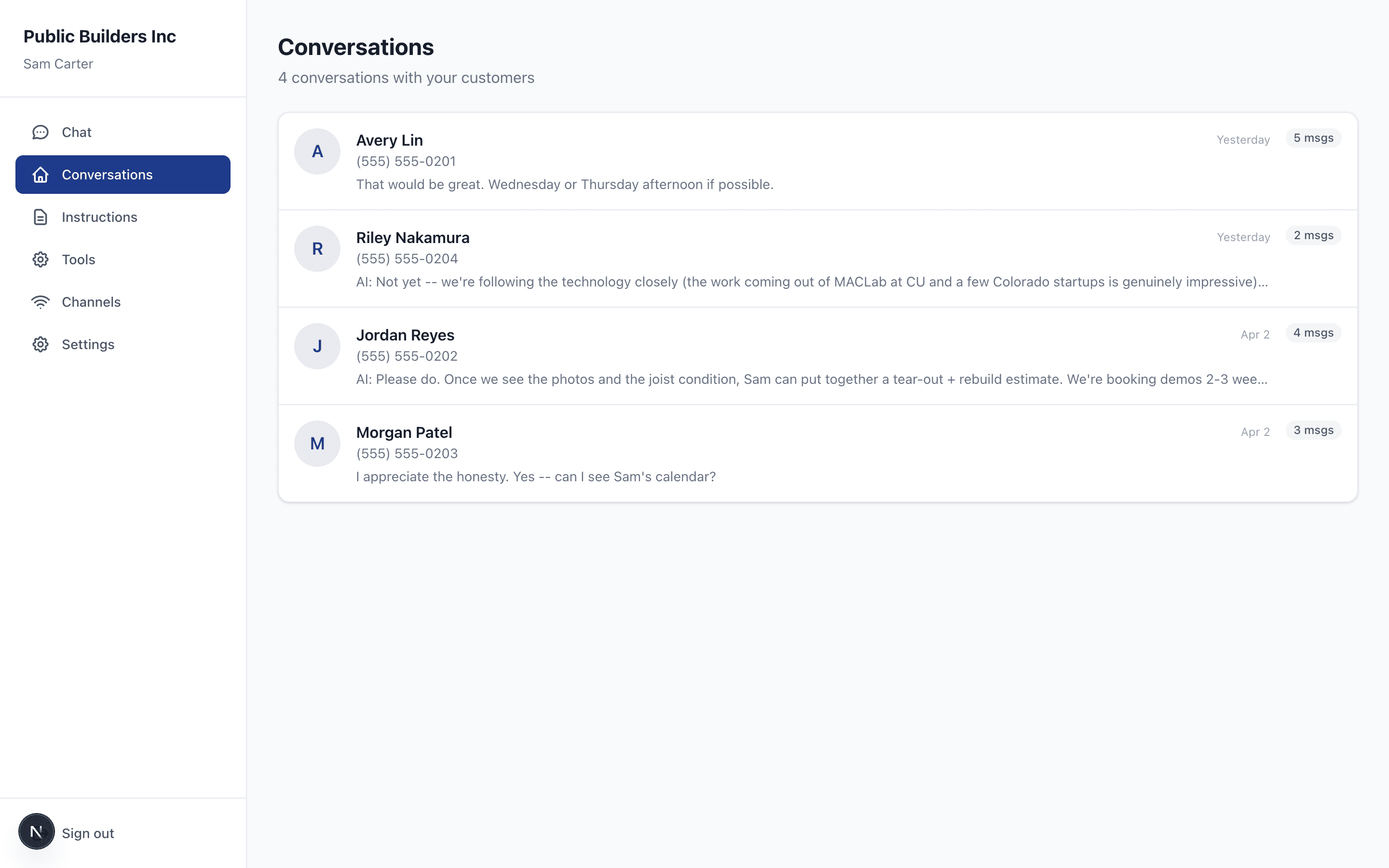
Progressive Disclosure as Data Labeling: A Different Kind of AI Safety Loop
Most AI safety tools block things. The owner tries to enable a feature. The system checks a policy. The policy says no. The feature stays off. The owner is annoyed and learns nothing.
We built something different. When an owner makes a configuration change that shifts the risk profile of their AI deployment, our system doesn't block — it teaches. It generates a contextual interface that explains what just changed, walks the owner through the implications, and captures their response as labeled data about how real businesses understand and accept risk.
The result is a strange hybrid: a customer experience that feels like progressive disclosure, an engineering surface that produces a continuously growing labeled dataset, and a safety model that gets stronger every time someone uses it.
This post is about why those three things are the same thing.
The Genie and the Wishes
There's an old story about a genie and three wishes. The lesson is usually framed as "be careful what you ask for." But the more interesting reading is structural: the genie grants exactly what is asked and the asker discovers, after the fact, that what they asked for and what they wanted were not the same thing.
A good genie would explain the wish before granting it. Not to refuse — to help the wisher see what they're actually asking for. The first wish gets you what you said. The third wish, after two failures, gets you what you meant.
This is the trust layer's job. Every configuration change to a public-facing AI is a wish. "Enable email tools." "Discuss pricing on the phone." "Send follow-up messages without my approval." Each of these requests is doing more than the words suggest. The owner is asking for capability, but they're also unknowingly asking for a specific risk profile, a specific failure mode, and a specific kind of trouble that only shows up after the fact.
We don't refuse these wishes. We explain them.
How the Interface Works
The trigger is the moment of configuration change. Our MCP write tools — update_instructions, update_tool_config, update_business_info — don't apply changes immediately. They route through the trust layer's evaluation engine first.
The engine scores the change against eight risk dimensions (autonomy, action capability, consequence severity, reversibility, audience exposure, domain sensitivity, identity representation, data sensitivity). If the change shifts any dimension upward, that dimension becomes the focus of an interface generated for this specific change.
The interface is not a static modal. It's generated by Claude, on demand, using a template plus the actual facts of the situation plus relevant content from our knowledge base. So when a plumber enables email tools, the interface they see is not a generic "are you sure?" warning. It's a specific explanation of what email tools mean for their deployment: "You're enabling your agent to send emails on your behalf. That means it can now reach people outside the people who texted you first. It also means a mistake reaches their inbox, where it lives forever and can be forwarded to anyone. Here's what other plumbers have learned about email guardrails. Here's how to scope what kinds of emails the agent is allowed to send."
The owner reads it. Clicks through. Selects guardrails. Acknowledges they understand. The change is then applied — with the guardrails baked in, because the owner just configured them.
The Air Canada chatbot case becomes a story they encounter the moment they're about to make the same mistake, not a warning they read on a marketing page they've forgotten by the time they're in the product.
Why This Is Different From a Modal Dialog
It would be easy to mistake this for a fancier consent flow. It's not, for three reasons.
First, the interface is generated, not authored. A modal dialog assumes the product team has anticipated every configuration the owner might attempt and written copy for it. That breaks the moment the product surface gets larger than a small team can hold in their head. Our interfaces are produced by Claude at the moment of need, from the actual change, the actual deployment context, and the current knowledge base. New configurations get coverage automatically.
Second, the owner's path through the interface is captured as labeling signal. Every choice they make — which guardrails they select, which they decline, which warnings they read carefully and which they skim, where they bail out, where they ask for clarification — gets stored as labeled data in our trust_layer_signals table. This is not analytics in the dashboard sense. It's training data in the model sense. The signal is about how a specific kind of business owner, in a specific situation, actually relates to a specific risk.
Third, the interface is the product, not a layer on top of the product. A modal blocks you from your goal. The trust layer interface is your goal — it's where the configuration change actually happens. You can't route around it because there's nothing to route around. The labeling loop is the configuration loop.
The Labeling Loop, Made Concrete
Here is what happens, end to end, when a plumber enables a new capability:
- Plumber clicks "enable email tools" in the portal (or asks Claude Desktop, or hits the MCP API directly — it's the same write handler).
- Write handler routes through the trust layer engine. The engine scores the change: action capability moves from 2 to 3, audience exposure moves from 1 to 2.
- The engine selects the appropriate interface template (
tools × safetyfor the action capability shift) and asks Claude to generate the interface using that template, the plumber's deployment facts, and KB content about email guardrails. - The portal renders the generated interface inline in the chat where the plumber was working.
- The plumber reads it. Reads the Air Canada anecdote. Decides which kinds of emails the agent should be allowed to send. Sets a daily send limit. Approves.
- The change is applied with the guardrails the plumber just configured. The trust layer logs:
- What the change was
- What the engine scored it as
- Which interface was shown
- Which guardrails the plumber accepted
- Which they declined
- How long they spent on the interface
- What they did next
That sixth step is the dataset. It's not synthetic. It's not gathered by paying labelers. It's not extracted from crawled forum posts. It's a continuous stream of how real owners, in real businesses, make real decisions about real AI deployments. Every customer interaction with the trust layer is a labeled example. Every configuration change is a vote on what the right safety scaffolding looks like for a particular kind of work.
Why This Compounds
The simple version of "AI safety as data collection" would be: log everything, train a classifier on it, eventually replace human review. That's not what's happening.
What's happening is more interesting. The labeling signal is being used to do four different things at once:
Calibrate the risk dimensions. The eight-dimension scoring system has weights. Those weights are educated guesses, derived from existing frameworks and incident reports. As the trust layer accumulates signals about which dimensions owners actually attend to versus which they skip past, the weights can be updated. The system learns which risks owners take seriously and which they need help recognizing.
Improve the interface generation. Some interfaces get read carefully. Others get speed-clicked. The signals tell us which template + context combinations actually communicate, and which don't. Templates that don't communicate get rewritten — by us, not by the labelers, but informed by them.
Map the failure landscape. When a deployment has an incident — the customer complains, the owner escalates, the AI does something embarrassing — we can trace back to the configuration change that introduced the risk and ask: did the trust layer surface the right interface? Did the owner understand it? Did they decline a guardrail they should have accepted? The labeling signal makes these questions answerable, not speculative.
Build a defensible position. The dataset is the moat. Anyone can copy the eight-dimension scoring framework — it's published, it's interactive, the criteria are documented. What they can't copy is the longitudinal record of how thousands of small businesses, across hundreds of deployments, made specific decisions about specific risks. That dataset only gets built by running the loop at scale, over time.
What This Is Not
This is not "AI safety theater." It's not adding a layer of warnings to make the lawyers happy. The interfaces are not optional — they're how configuration changes actually get applied. There is no "skip" button.
This is not "RLHF for safety." We're not asking owners to rank model outputs. We're asking them to reason about their own deployment, in their own context, about decisions that affect their own business. The signal is about deployment configuration, not model behavior.
This is not "compliance as a service." We're not generating audit trails for regulators (though the audit trails do exist as a side effect). The point is to help the owner understand what they're shipping, before they ship it, while they're still in a position to change their mind.
This is not "guardrails." Guardrails are static rules that block actions. The trust layer is a dynamic explanation system that helps owners configure the right guardrails for their specific situation. Two different plumbers will end up with different guardrails. That's the system working correctly.
What's Next
The current implementation has the engine, the interface generator, the signal capture, and the rendering surface. What it doesn't yet have is the full labeling-to-improvement loop. The signals are being captured. They're not yet being fed back into the scoring weights or the template selection logic. That's the next phase.
The longer arc is more ambitious. The trust layer is the first product where the customer experience and the labeling pipeline are the same surface. If it works — if the owners actually do learn from the interfaces, and the signal does sharpen the system over time — then the same architecture applies anywhere a non-expert needs to make a high-stakes decision they don't yet have the framework for. Construction permitting. Insurance underwriting. Medical informed consent. Anywhere the wish-grantor should explain the wish.
For now, it works inside one narrow domain: helping a plumber decide whether her AI should be allowed to send email. That's a small problem. But it's a small problem with a big shape, and the shape is what we're after.
Stop losing jobs to missed calls
AI texts your missed callers back in 30 seconds. Real conversations, not templates. 14-day free trial — no card required.
Related Articles
Why Our AI Cites Its Sources -- and How We Wired It Through Claude's API
Knowledge sources passed as Claude API document blocks return citations linked to specific generated text. The portal renders cited claims with inline source badges, so owners can see exactly where every answer came from.
Risk Scoring for Public-Facing AI: Eight Dimensions, Compound Scores, Hard Stops
A scoring engine that evaluates AI deployments on eight independent risk dimensions, combines them with a weighted geometric mean, and hard-stops dangerous combinations. Runs inside MCP write tools so every configuration change is evaluated before it ships.
Why We Don't Sanitize User Messages in Our AI Agent
The correct boundary for prompt injection defense is between system content and user content -- not between safe and unsafe words. Here's why regex filters on user input do more harm than good.